
Introduction to Artificial Neural Networks (ANNs)

Artificial Neural Networks (ANNs), inspired by the human brain system, are based on a collection of units of neurons that are connected one to another to process and send information.
A very basic or a simplest neural network composes of only a single neuron, some inputs  and a bias b as illustrated in the following figure.
and a bias b as illustrated in the following figure.
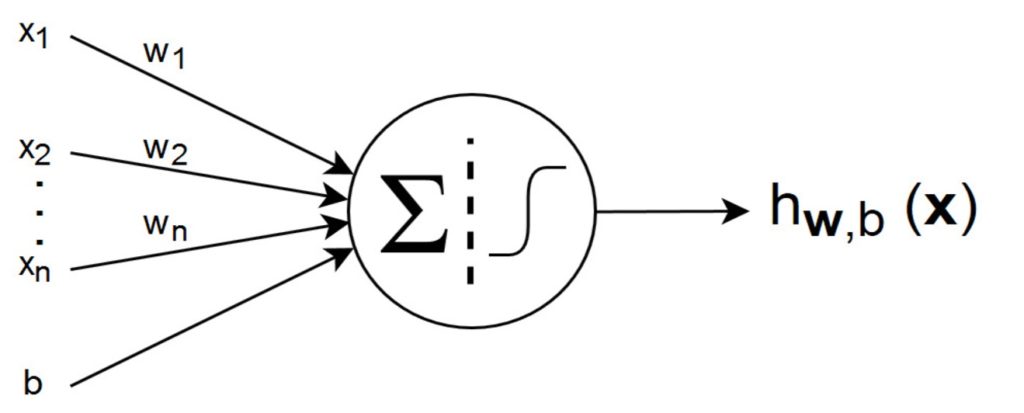
All the inputs and the bias are connected to this neuron. These connections are called the synapses where every synapse has the weight W.
The hypothesis output of this simplest neural network is written as:
(1) 
The function of  is called the activation function.
is called the activation function.
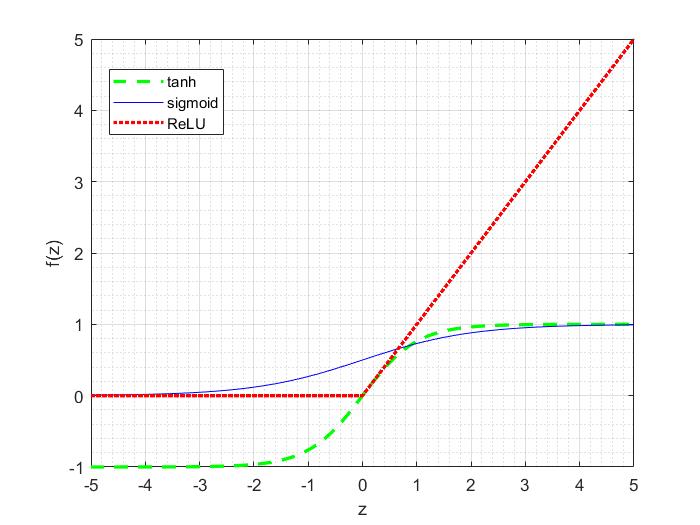
There are many kinds of activation functions used in NNs implementation, the most commonly used are step function, sigmoid function, tanh and Rectifier Linear Unit (ReLu).
Activation Function
In the above description of the simplest neural network, it uses a sigmoid function as the activation function.
The sigmoid function is one of the popular activation functions used in the neural network systems. It is written by:
(2) 
It is important to be noticed that there are other common choices of the activation functions, they are hyperbolic tangent or tanh and rectified linear unit (ReLU).
The tanh function is written as:
(3) 
The rectified linear activation function is given by:
(4) 
In practice, for deep Neural Networks, rectified linear function often works better than thesigmoid and the tanh functions.
The following figure shows the plots of the sigmoid, tanh and rectified linear functions (ReLU).
Multi-Layer Neural Network
The simplest neural network described above is a very limited model. To form a multi-layer neural network, we can hook together the simple neurons. The output of a neuron can be the input of another.
The following figure shows a simple multi-layer neural network with two hidden layers.
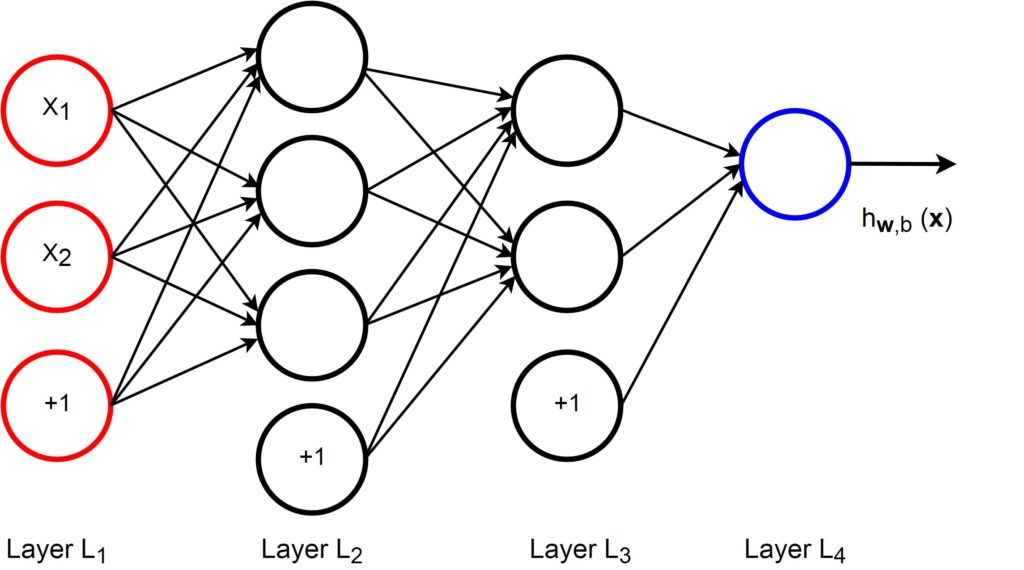
This network has four layers with two inputs  and
and  in the input layer (layer
in the input layer (layer  ) and one output in the output layer (layer
) and one output in the output layer (layer  ). It has two hidden layers, layer
). It has two hidden layers, layer  and layer
and layer  . The circles labeled “+1” are called bias units that correspond to the intercept term.
. The circles labeled “+1” are called bias units that correspond to the intercept term.
Feed Forward Propagation
Now, we’re going to analyze this multi-layer neural network.
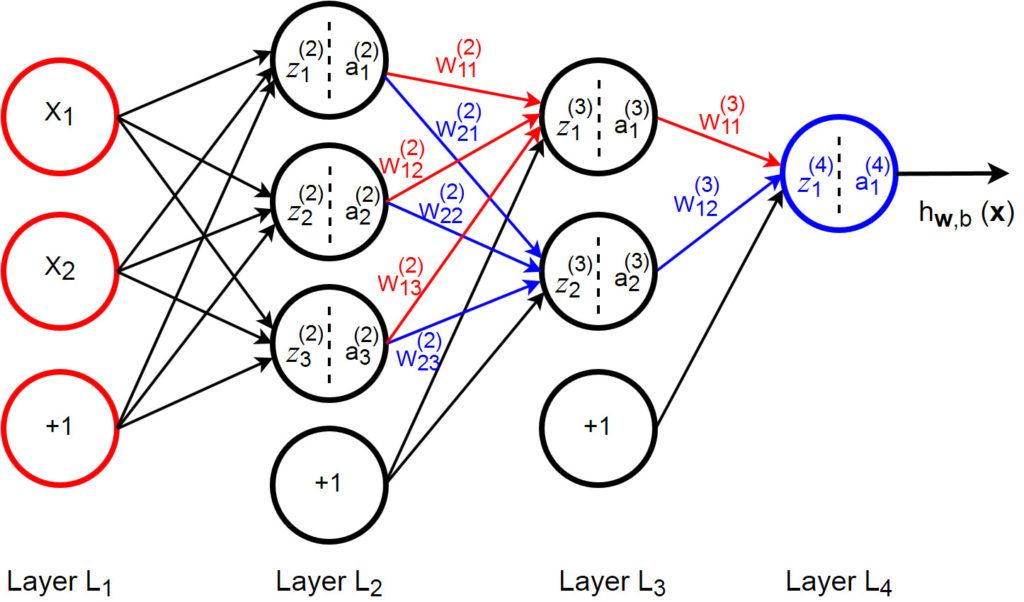
We write  to denote the parameter (or weight) associated with the connection between unit
to denote the parameter (or weight) associated with the connection between unit  in layer
in layer  , and unit
, and unit  in layer
in layer  . The number of layers in the network is denoted by
. The number of layers in the network is denoted by  . So, the above multi-layer neural network model has =4.
. So, the above multi-layer neural network model has =4.
The activation of unit in layer is denoted by  . For example: for
. For example: for  , we denote
, we denote  for activation of unit in layer 1.
for activation of unit in layer 1.
We also use  to denote the th input.
to denote the th input.
Given a fixed setting of the parameters  and
and  , our neural network defines a hypothesis
, our neural network defines a hypothesis  . It outputs a real number.
. It outputs a real number.
Now, we are going to look particularly at the last two layers, and .
The layer produces the output hypothesis and the layer is the last hidden layer. Specifically, the computation of the activation function in the layer can be derived as the following:
(5) 
The hypothesis of the output of this neural network can be written as:
(6) 
If we let  denoted as the total weighted sum of inputs to unit in layer , including the bias term, we will have:
denoted as the total weighted sum of inputs to unit in layer , including the bias term, we will have:
(7) 
so that: 
or, for the computation of the next layer is:
(8) 
Using matrix-vectorial notation, the above equation 8 can be written as follows:
(9) 
so that:
(10) 
The output of 6 can be written as:
(11) 
Back Propagation
Suppose we have a fixed training set  of
of  training examples. We can train our neural network using batch gradient descent. For a single training example, the cost function with respect to single example is written as one-half square error as follows:
training examples. We can train our neural network using batch gradient descent. For a single training example, the cost function with respect to single example is written as one-half square error as follows:
(12) 
Given a training set of examples, we then define the overall cost function to be:
(13) ![\begin{equation*} \begin{split} J(W,b;x,y) & = [\frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)})] +\frac{\lambda}{2} \sum_{l=1}^{n_l-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_{l+1}} (W_{ji}^{(l)})^2\\ & = [\frac{1}{m} \sum_{i=1}^m ( \frac{1}{2} \Vert h_{W,b}( x^{(i)})-y^{(i)} \Vert ^2 )] +\frac{\lambda}{2} \sum_{l=1}^{n_l-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_{l+1}} (W_{ji}^{(l)})^2\\ \end{split} \end{equation*}](https://machinelearningspace.com/wp-content/ql-cache/quicklatex.com-9cad28b32a7cb198c03b31f49192a991_l3.png "Rendered by QuickLaTeX.com")
The first term is an average sum-of-squares error term. The second term is a regularization term (also called a weight decay term) that tends to decrease the magnitude of the weights, and helps prevent over-fitting. The weight decay parameter  controls the relative importance of the two terms.
controls the relative importance of the two terms.
Gradient Descent
When we train the NNs, the goal is to minimize J(W,b) as a function of W and b. So basically, we initialize all parameters and  to small random values and then apply the Gradient Descent algorithm to optimize these parameters.
to small random values and then apply the Gradient Descent algorithm to optimize these parameters.
To implement gradient descent algorithm, the parameters of the gradient  must be updated as follows:
must be updated as follows:
(14) 
where  is the learning rate.
is the learning rate.
To do back propagation completely, the derivative of the overall cost function J(W,b) can be computed as:
(15) ![\begin{equation*} \begin{split} \frac{\partial}{W_{ij}^{(l)}} J(W,b) & = \left[ \frac{1}{m} \sum_{i=1}^m \frac{\partial}{W_{ij}^{(l)}} J(W,b;x^{(i)},y^{(i)})\right] +\lambda W_{ij}^{(l)}\\ \frac{\partial}{b_i^{(l)}} J(W,b) & = \left[ \frac{1}{m} \sum_{i=1}^m \frac{\partial}{b_i^{(l)}} J(W,b;x^{(i)},y^{(i)})\right]\\ \end{split} \end{equation*}](https://machinelearningspace.com/wp-content/ql-cache/quicklatex.com-177b642781f3ec5edb5d4a8ef2fbf7c9_l3.png "Rendered by QuickLaTeX.com")
Detail of back propagation algorithm is:
- Perform a feedforward pass, computing the activations for layers
 and so on up to the output layer
and so on up to the output layer  .
. - For each output unit in layer (the output layer), set:
(16)

- For

For each node in layer, set:(17)

- Compute the desired partial derivatives, which are given as:
(18)

In the matrix-vectorial notation, the algorithm above can be re-written as:
- Perform a feedforward pass by computing the activations for layers and so on up to the output layer .
- For output layer (layer ) , set:
(19)

- For , set:
(20)

- Compute the desired partial derivatives, which are given as:
(21)

Now, we are ready to derive the full Gradient Descent Algorithm.
- Set

- For
 to ,
to ,
(a) Use back propagation to compute and
and 
(b)
(c)
- Update the parameters:
(22)
![\begin{equation*} \begin{split} W^{(l)} & = W^{(l)} - \alpha \left[ \left( \frac{1}{m}\triangle W^{(l)} \right) + \lambda W^{(l)} \right] \\ b^{(l)} & = b^{(l)} - \alpha \left[ \frac{1}{m}\triangle b^{(l)} \right] \\ \end{split} \end{equation*}](https://machinelearningspace.com/wp-content/ql-cache/quicklatex.com-142cdf970cf9230b0f9272b29f78453a_l3.png "Rendered by QuickLaTeX.com")
Finally, the NNs now can be trained by repeating the gradient descent steps to reduce the cost function  .
.
Reference
Andrew Ng et.al, ‘Welcome to the Deep Learning Tutorial!: Multi-Layer Neural Network’, http://deeplearning.stanford.edu/tutorial